-
Courriel
service@h3c.com
- Téléphone
-
Adresse
Société H3C no.466 Yanghe Road, Binjiang District, Hangzhou
Catégories de produits
Xinhua santech Co., Ltd

Base de données distribuée H3C seasql MPP
NégociableMise à jour sur12/28
- Modèle
- Nature du fabricant
- producteurs
- Catégorie de produit
- Lieu d'origine
Vue d'ensemble
- au cours de la dernière décennie, l'industrie de l'Internet, après avoir évolué lentement à rapidement, a accumulé une énorme quantité d'informations et de données, et dans un contexte de croissance explosive des données, une nouvelle méthode de calcul est nécessaire pour cibler les données massives. Les méthodes de calcul traditionnelles ne sont plus suffisantes pour faire face au traitement de grandes quantités de données, et les inconvénients sont évidents, en plus d'être coûteux, il est techniquement difficile de répondre aux indicateurs de performance de calcul de données, le mode Scale - up de l'hôte traditionnel rencontre des goulots d'étranglement, l'architecture SMP (Symmetrical Multi - Processing) est difficile à mettre à l'échelle et ne répond pas aux exigences de calcul de grandes quantités de données en termes de calcul CPU et de débit io. Dans ce contexte, la base de données distribuée H3C seasql MPP avec des capacités d'analyse de performance ultra - puissantes pour gérer des volumes de données de niveau pétaoctet a vu le jour. H3C seasql MPP est basé sur une architecture MPP (massively Parallel Processing) sans partage, avec de bonnes capacités d'évolutivité élastique et linéaire, des technologies intégrées de stockage parallèle, de communication parallèle, de calcul parallèle et d'optimisation, compatibles avec les normes SQL, des capacités de stockage, de traitement et d'analyse en temps réel puissantes, efficaces et sécurisées de pétaoctets de données structurées, semi - structurées et non structurées, tout en prenant en charge des charges hybrides couvrant des activités de type oltp, ouvrant la voie à une boucle fermée d'activité - Données - informations - entreprise pour les clients, déployable dans le cloud privé ou nu de l'entreprise, supportant Un grand nombre de systèmes de production de base dans divers secteurs, notamment la finance, les valeurs mobilières, les télécommunications, le Gouvernement, la fabrication, le transport et plus encore.
Détails du produit
Architecture du système
Pour aider les clients de tous les horizons à relever les défis posés par l'ère du Big Data, H3C a conçu une suite de plateformes de traitement de données volumineuses hautes performances utilisant un cadre de calcul pour la fusion de bases de données distribuées Hadoop et MPP afin de fournir aux utilisateurs une solution complète de plateforme Big Data comprenant une gamme complète de fonctionnalités telles que la conversion d'acquisition de données, le calcul de stockage, l'exploration analytique, l'échange partagé, la présentation bi et la gestion des opérations et de l'entretien pour les aider à construire des systèmes de traitement de données volumineux, à découvrir la valeur intrinsèque des données et à saisir de nouvelles opportunités de marché.
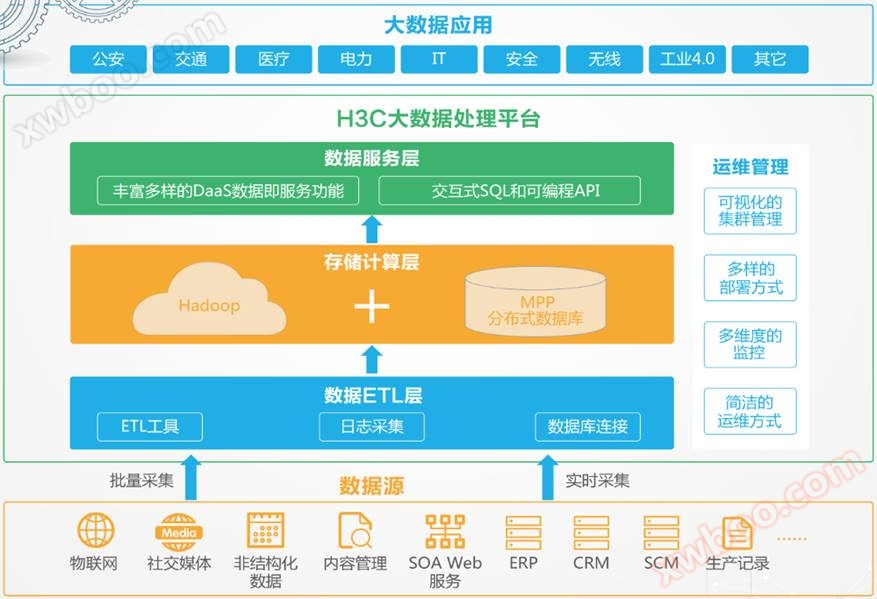
Seasql MPP prend en charge le déploiement de machines physiques sur site, ainsi que le déploiement sur un cloud privé, la source de données peut être le stockage local, HDFS、 Le stockage en nuage ou d'autres bases de données relationnelles telles qu'Oracle, MySQL, etc. sont intégrées à la base de données seasql MPP via des outils ETL ou Kafka. La base de données distribuée MPP seasql est basée sur une architecture massivement parallèle sans partage, avec des capacités de traitement de données de niveau pétaoctet et un noyau basé sur le noyau PostgreSQL avec beaucoup d'optimisation, fournissant un optimiseur de requête puissant et une compatibilité parfaite avec SQL. Au niveau des interfaces, seasql MPP fournit des interfaces pour les langages de programmation courants python / R / Java / perl / C en plus des interfaces JDBC / ODBC standard, ainsi que des interfaces pour les bibliothèques d'apprentissage automatique madlib, la récupération de texte intégral et POSTGIS qui fournissent des appels de couche.

Seasql MPP est une architecture distribuée avec une grande capacité d'extension latérale qui permet l'interconnexion de milliers de nœuds et prend en charge des milliers de CPU. Ses puissantes capacités de traitement des données et de calcul sont adaptées aux scénarios suivants:
• idéal pour les applications axées sur l'analyse, telles que la création d'ods / Edw d'entreprise, de Data marts, etc.
• idéal pour les applications nécessitant le traitement de grandes quantités de données, telles que les entrepôts de données, la Business Intelligence, etc.
• convient à l'analyse et à l'exploration de données hors ligne, telles que l'analyse du comportement des clients, les portraits de personnes, la modélisation prédictive du comportement, etc.
Caractéristiques fonctionnelles
H3C seasql MPP est une base de données distribuée basée sur PostgreSQL qui adopte l'architecture Shared nothing, l'hôte, le système d'exploitation, la mémoire, le stockage sont tous auto - contrôlés et il n'y a pas de partage. Les principales caractéristiques de la base de données H3C seasql MPP sont les suivantes:
· architecture de traitement parallèle à grande échelle.
· supporte à la fois la mémoire de ligne et la mémoire de colonne. Chaque table ou partition de table peut être stockée et compressée séparément par l'Administrateur en fonction des besoins de l'application.
· prend en charge plusieurs méthodes de compression, y compris zlib, rle, etc.
· prend en charge la table de partition à plusieurs niveaux, la partition prend en charge plusieurs modes, y compris la portée, la liste, etc.
· supporte les index tels que B - tree, bitmap et GIST.
· les mécanismes d'authentification prennent en charge de nombreuses façons, y compris LDAP et Kerberos, entre autres.
Prise en charge étendue des langages: seasql MPP prend en charge l'implémentation de fonctions personnalisées par l'utilisateur dans plusieurs langages populaires, notamment Python, R, Java, Perl, C / C + +, etc.
Traitement de l'information géographique: grâce à l'intégration de POSTGIS, seasql MPP prend en charge le stockage et l'analyse de l'information géographique.
Bibliothèque d'algorithmes d'exploration de données intégrée: avec la Bibliothèque d'algorithmes madlib (maintenant Apache incubation Project), vous pouvez intégrer des dizaines d'algorithmes d'analyse et d'exploration de données courants dans une base de données seasql MPP, y compris la régression logistique, les arbres de décision, les forêts aléatoires, etc. Il n'est pas nécessaire d'écrire du Code algorithmique, tous les algorithmes peuvent être utilisés via SQL.
· récupération de texte: seasql MPP peut prendre en charge des fonctions de récupération de texte intégral efficaces, flexibles et riches. Co - administré avec madlib, l'analyse et l'exploration de texte en parallèle sont possibles.
· chargement haute performance, utilisant la technologie MPP, offrant des performances de chargement pour le volume de données au niveau de petabyte.
· optimisation des requêtes de flux de travail Big Data.
· stockage et exécution de données polymorphes.
· capacités avancées de machine learning basées sur Apache madlib.
· prise en charge des normes SQL 92 ANSI / ISO, SQL 99 ANSI / ISO, SQL 2003 ANSI / ISO, SQL 2006 ANSI / ISO, prise en charge des spécifications d'interface internationales telles que c API, ODBC, JDBC, prise en charge des syntaxes DDL, DML, DCL, prise en charge des types de Données de base, des contraintes d'intégrité de base, de la gestion de table de base, des critères de recherche, des connexions de table, des sous - requêtes, des insertions, des modifications, des suppressions, des contrôles de transaction.
Caractéristiques avantageuses
Déploiement Cloud
Seasql MPP prend en charge l'installation de déploiement de la plate - forme Cloud cloudos5.0, capable de prendre en charge les déploiements Cloud. Grâce à l'interface cloudos, les utilisateurs peuvent contrôler toutes les ressources de manière unifiée et gérer la planification de manière uniforme, ce qui leur permet de gérer les ressources allouées de manière flexible et d'améliorer l'utilisation globale des ressources.

Expansion de capacité sans interruption
Les bases de données MPP seasql peuvent être étendues de deux manières en fonction des besoins du client: l'extension hôte et l'extension instance. Il suffit de mettre à jour les métadonnées de la table système pour compléter l'extension, il n'est pas nécessaire d'arrêter l'opération sur la base de données, et l'algorithme Jump consistent Hash est utilisé pour réduire considérablement le Mouvement des données lors de la redistribution des données.
Stockage hybride de rang
La base de données MPP seasql fournit de nombreux types de modèles de stockage: stockage en ligne, stockage en colonne, stockage hybride en ligne, le modèle de stockage des données peut être formulé en fonction des besoins de l'entreprise.

Fonctions OLAP
Seasql MPP fournit des fonctions OLAP riches, notamment: rollup, cube, fonction de fenêtre, opérations récursives, etc. pour soutenir des opérations analytiques complexes axées sur l'aide à la décision pour les décideurs et les cadres supérieurs. Le traitement des requêtes complexes pour les volumes de données volumineux peut être effectué rapidement et de manière flexible, à la demande des analystes, afin qu'ils puissent comprendre avec précision la situation opérationnelle de l'entreprise, comprendre les besoins des personnes desservies et élaborer le bon plan.
Multi - locataires
La fonctionnalité Multi - tenant de la base de données MPP seasql peut diviser une base de données en plusieurs locataires à utiliser, les ressources physiques des différents locataires sont isolées les unes des autres, la fonctionnalité Multi - tenant reflète principalement les avantages suivants:
Les exigences des différents locataires en matière de ressources physiques ne sont pas les mêmes, les ressources sont isolées les unes des autres et ne perturbent pas les autres, ce qui empêche certains locataires de saisir les ressources d'autres utilisateurs pendant les pics d'activité.
Les données des locataires sont isolées les unes des autres, ce qui améliore la sécurité des données.
Lorsque les ressources système sont inactives, les ressources CPU et mémoire peuvent être utilisées de manière élastique, lorsque les ressources sont plus occupées, les ressources entre les locataires sont limitées en fonction des paramètres définis, ce qui améliore l'utilisation des ressources dans l'ensemble du système.
Forte capacité de chargement parallèle
Les mesures de performance d'importation des données jouent un rôle important dans l'expérience d'utilisation de l'entrepôt de données, la base de données MPP seasql peut utiliser les ressources des nœuds appartenant à l'ensemble du cluster lors du chargement des données, les performances de chargement augmentent linéairement avec le nombre de nœuds et le taux de chargement des données peut atteindre 20 to / heure dans un cluster à grande échelle.
Bibliothèque madlib Machine Learning intégrée
Madlib n'est pas destiné aux programmeurs, mais au développement de bases de données ou DBA, et combine la simplicité d'utilisation de SQL avec des algorithmes sophistiqués d'exploration de données pour tirer pleinement parti des avantages et des caractéristiques des deux et améliorer considérablement l'efficacité du développement des développeurs.
Pour les utilisateurs, madlib fournit des fonctions qui peuvent être appelées dans des requêtes SQL, qui incluent non seulement des opérations algébriques linéaires de base et des fonctions statistiques, mais également des fonctions de modèle d'apprentissage automatique ou d'exploration de données couramment utilisées et prêtes à l'emploi. L'utilisateur n'a pas besoin de comprendre en profondeur les détails de la mise en œuvre du programme de l'algorithme, il suffit de clarifier la méthode d'utilisation de la fonction, d'améliorer considérablement l'efficacité du développement et d'économiser les coûts de développement.

Traitement des données géospatiales POSTGIS intégré
POSTGIS est une extension du système de base de données relationnelle objet PostgreSQL, qui transforme le système de gestion de base de données PostgreSQL en base de données spatiale en ajoutant la prise en charge des types de données spatiales, des index spatiaux et des fonctions spatiales à PostgreSQL.
Seasql MPP Integration POSTGIS SPACE DATABASE intègre complètement les données spatiales et les bases de données relationnelles d'objets, permettant une transition centrée sur les SIG vers les bases de données. De cette façon, les utilisateurs n’ont pas besoin d’un moteur de données SIG spécialisé pour traiter et manipuler les données spatiales, et les applications n’ont besoin que de manipuler facilement les données spatiales via le langage SQL.
Cryptage transparent
Le module seasql MPP Transparent Encryption implémente le chiffrement de l'ensemble de la base de données, qui est totalement imperceptible pour le client. Crypter les données lorsqu'un bloc de données est écrit sur le disque; Lorsque les données sont lues à partir du disque, le déchiffrement est effectué. Vous pouvez garantir que les données stockées sur le disque sont cryptées en permanence et que même l'acquisition du contenu du disque ne peut pas lire les données en texte clair à l'intérieur. En même temps, le niveau métier est totalement insensible aux actions cryptographiques et ne nécessite aucune modification adaptée au cryptage. La méthode de chiffrement utilise le mode de chiffrement xts d'AES, qui garantit la sécurité du chiffrement des données.
Désensibilisation des données
La désensibilisation des données (Data masking), également connue sous le nom de blanchiment des données, de dépersonnalisation des données ou de déformation des données. Se réfère à la déformation des données sur certaines informations sensibles par des règles de désensibilisation, permettant une protection fiable des données confidentielles sensibles. En ce qui concerne les données de sécurité du client ou certaines données commercialement sensibles, sans enfreindre les règles du système, la modification des données réelles et la fourniture d'un test d'utilisation, telles que les informations personnelles telles que le numéro d'identification, le numéro de téléphone portable, le numéro de carte, le numéro de client, etc., nécessitent une désensibilisation des données.
La base de données MPP seasql fournit des moyens diversifiés de désensibilisation, après avoir défini les règles de désensibilisation, les utilisateurs peuvent accéder aux données de désensibilisation de deux manières:
Désensibilisation statique:Supprimez les informations sensibles à l'intérieur de la bibliothèque et les données sensibles à l'intérieur de la base de données sont écrasées irrécupérables.
Désensibilisation dynamique:Masquer les informations sensibles pour l'utilisateur spécifié, d'autres utilisateurs qui n'ont pas été désensibilisés auront toujours accès aux données brutes.
La Fédération données fdw
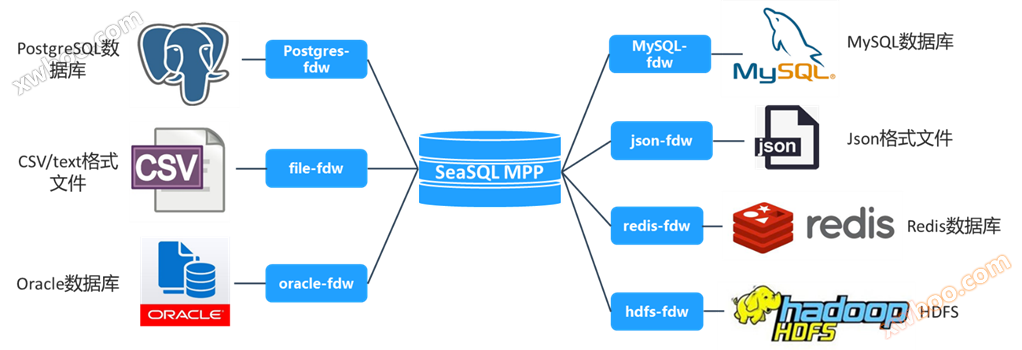
Fdw est une implémentation du standard SQL SQL / MED (SQL Management of external data). Fdw fournit une gamme d'interfaces communes unifiées qui permettent aux extensions de s'intégrer facilement dans des sections de base telles que l'optimisation, l'exécution, l'analyse, la mise à jour et les statistiques, ainsi qu'en profondeur avec seasql, ce qui permet d'interroger et de manipuler directement des sources de données externes avec des instructions SQL. Par exemple, fdw pour MySQL permet aux utilisateurs d'interroger, de trier, de regrouper, de filtrer, de joindre et même d'insérer et de mettre à jour directement les données d'une base de données MySQL comme s'ils manipulaient une table locale.
Selon la source de données, le module fdw implémenté par seasql comprend: postgres_fdw、file_fdw、oracle_fdw、mysql_fdw、json_fdw、redis_fdw、hdfs_dfw, Comme le montre l'image ci - dessous:
Roaringbitmap compression bitmap
Roaringbitmap est un algorithme de compression bitmap très efficace qui peut améliorer efficacement l'efficacité de l'utilisation de la mémoire bitmap et résoudre le problème des bitmaps épars qui ne s'adaptent pas au stockage épais. Bitmap bitcomputing est idéal pour le calcul de base de données volumineuses et est souvent utilisé dans les calculs tels que le déduplication, le filtrage d'étiquettes, les séries chronologiques, etc. Gpdb - roaringbitmap le plugin gpdb - roaringbitmap intègre la fonctionnalité roaringbitmap dans une base de données MPP seasql, offrant un support natif pour les fonctions de base de données, les opérateurs, l'agrégation et plus encore en tant que type de données.
Produit similaire Recommander




